 |
High Performance Computing (HPC) allows scientists and engineers to solve complex, compute-intensive problems such as computational fluid dynamics (CFD), weather forecasting, and genomics. HPC applications typically require instances with high memory bandwidth, a low latency, high bandwidth network interconnect and access to a fast parallel file system.
Many customers have turned to AWS to run their HPC workloads. For example, Descartes Labs used AWS to power a TOP500 LINPACK benchmarking (the most powerful commercially available computer systems) run that delivered 1.93 PFLOPS, landing at position 136 on the TOP500 list in June 2019. That run made use of 41,472 cores on a cluster of Amazon EC2 C5 instances. Last year Descartes Labs ran the LINPACK benchmark again and placed within the top 40 on the June 2021 TOP500 list with 172,692 cores on a cluster of EC2 instances, which represents a 417 percent performance increase in just two years.
AWS enables you to increase the speed of research and reduce time-to-results by running HPC in the cloud and scaling to tens of thousands of parallel tasks that wouldn’t be practical in most on-premises environments. AWS helps you reduce costs by providing CPU, GPU, and FPGA instances on-demand, Elastic Fabric Adapter (EFA), an EC2 network device that improves throughput and scaling tightly coupled workloads, and AWS ParallelCluster, an open-source cluster management tool that makes it easy for you to deploy and manage HPC clusters on AWS.
Announcing EC2 Hpc6a Instances for HPC Workloads
Customers today across various industries use compute-optimized EFA-enabled Amazon EC2 instances (for example, C5n, R5n, M5n, and M5zn) to maximize the performance of a variety of HPC workloads, but as these workloads scale to tens of thousands of cores, cost-efficiency becomes increasingly important. We have found that customers are not only looking to optimize performance for their HPC workloads but want to optimize costs as well.
As we pre-announced in November 2021, Hpc6a, a new HPC-optimized EC2 instance, is generally available beginning today. This instance delivers 100 Gbps networking through EFA with 96 third-generation AMD EPYC™ processor (Milan) cores with 384 GB RAM, and offers up to 65 percent better price-performance over comparable x86-based compute-optimized instances.
You can launch Hpc6a instances today in the US East (Ohio) and GovCloud (US-West) Regions in On-Demand and Dedicated Hosting or as part of a Savings Plan. Here are the detailed specs:
| Instance Name | CPUs* | RAM | EFA Network Bandwidth | Attached Storage |
| hpc6a.48xlarge | 96 | 384 GiB | Up to 100 Gbps | EBS Only |
*Hpc6a instances have simultaneous multi-threading disabled to optimize for HPC codes. This means that unlike other EC2 instances, Hpc6a vCPUs are physical cores, not threads.
To enable predictable thread performance and efficient scheduling for HPC workloads, simultaneous multi-threading is disabled. Thanks to AWS Nitro System, no cores are held back for the hypervisor, making all cores available to your code.
Hpc6a instances introduce a number of targeted features to deliver cost and performance optimizations for customers running tightly coupled HPC workloads that rely on high levels of inter-instance communications. These instances enable EFA networking bandwidth of 100 Gbps and are designed to efficiently scale large tightly coupled clusters within a single Availability Zone.
We hear from many of our engineering customers, such as those in the automotive sector, that they want to reduce the need for physical testing and move towards an increasingly virtual simulation-based product design process faster at a lower cost.
According to our benchmarking results for Siemens Simcenter STAR-CCM+ automotive CFD simulation, when the Hpc6a scales up to 400 nodes (approximately 40,000 cores), with the help of EFA networking, it is able to maintain approximately 100 percent scaling efficiency. Hpc6a instance shows 70 percent lower cost compared to c5n, meaning companies can deliver new designs faster and at a lower cost when using Hpc6a instances. This means companies can deliver new designs faster and at a lower cost when using Hpc6a instances.
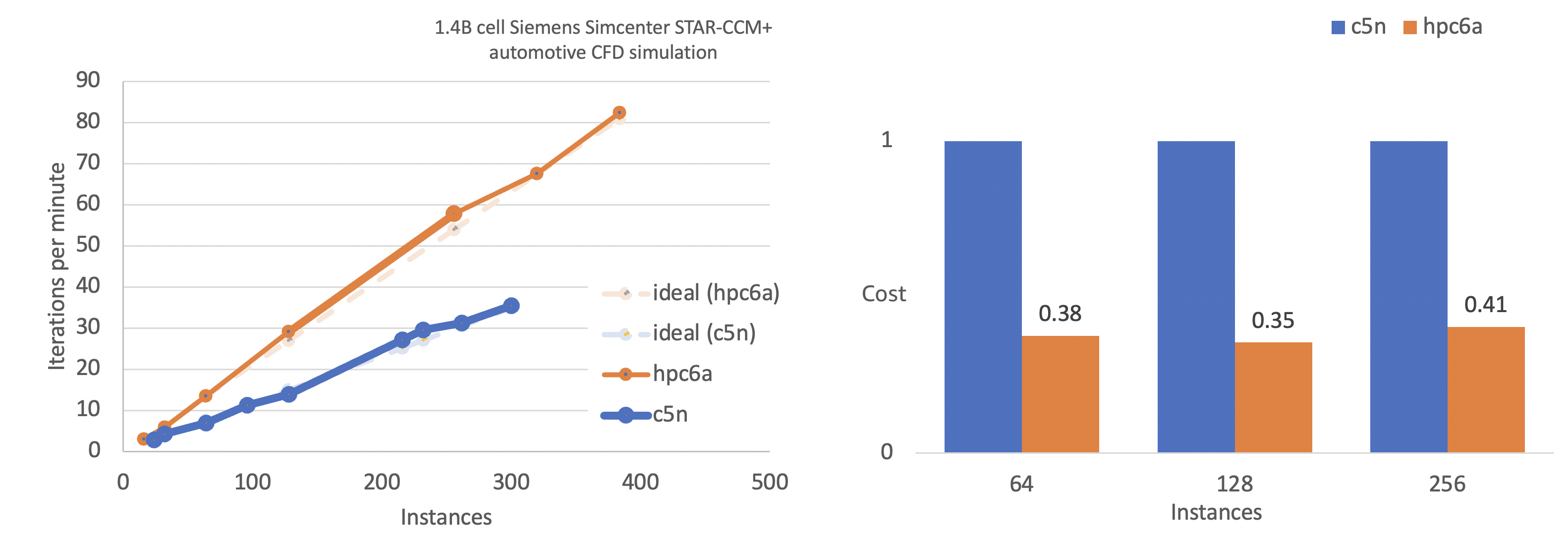
You can use the Hpc6a instance with AMD EPYC third-generation (Milan) processors to run your largest and most complex HPC simulations on EC2 and optimize for cost and performance. Customers can also use the new Hpc6a instances with AWS Batch and AWS ParallelCluster to simplify workload submission and cluster creation.
To learn more, visit our Hpc6a instance page and get in touch with our HPC team, AWS re:Post for EC2, or through your usual AWS Support contacts.
— Channy