 |
In March 2023, AWS and NVIDIA announced a multipart collaboration focused on building the most scalable, on-demand artificial intelligence (AI) infrastructure optimized for training increasingly complex large language models (LLMs) and developing generative AI applications.
We preannounced Amazon Elastic Compute Cloud (Amazon EC2) P5 instances powered by NVIDIA H100 Tensor Core GPUs and AWS’s latest networking and scalability that will deliver up to 20 exaflops of compute performance for building and training the largest machine learning (ML) models. This announcement is the product of more than a decade of collaboration between AWS and NVIDIA, delivering the visual computing, AI, and high performance computing (HPC) clusters across the Cluster GPU (cg1) instances (2010), G2 (2013), P2 (2016), P3 (2017), G3 (2017), P3dn (2018), G4 (2019), P4 (2020), G5 (2021), and P4de instances (2022).
Most notably, ML model sizes are now reaching trillions of parameters. But this complexity has increased customers’ time to train, where the latest LLMs are now trained over the course of multiple months. HPC customers also exhibit similar trends. With the fidelity of HPC customer data collection increasing and data sets reaching exabyte scale, customers are looking for ways to enable faster time to solution across increasingly complex applications.
Introducing EC2 P5 Instances
Today, we are announcing the general availability of Amazon EC2 P5 instances, the next-generation GPU instances to address those customer needs for high performance and scalability in AI/ML and HPC workloads. P5 instances are powered by the latest NVIDIA H100 Tensor Core GPUs and will provide a reduction of up to 6 times in training time (from days to hours) compared to previous generation GPU-based instances. This performance increase will enable customers to see up to 40 percent lower training costs.
P5 instances provide 8 x NVIDIA H100 Tensor Core GPUs with 640 GB of high bandwidth GPU memory, 3rd Gen AMD EPYC processors, 2 TB of system memory, and 30 TB of local NVMe storage. P5 instances also provide 3200 Gbps of aggregate network bandwidth with support for GPUDirect RDMA, enabling lower latency and efficient scale-out performance by bypassing the CPU on internode communication.
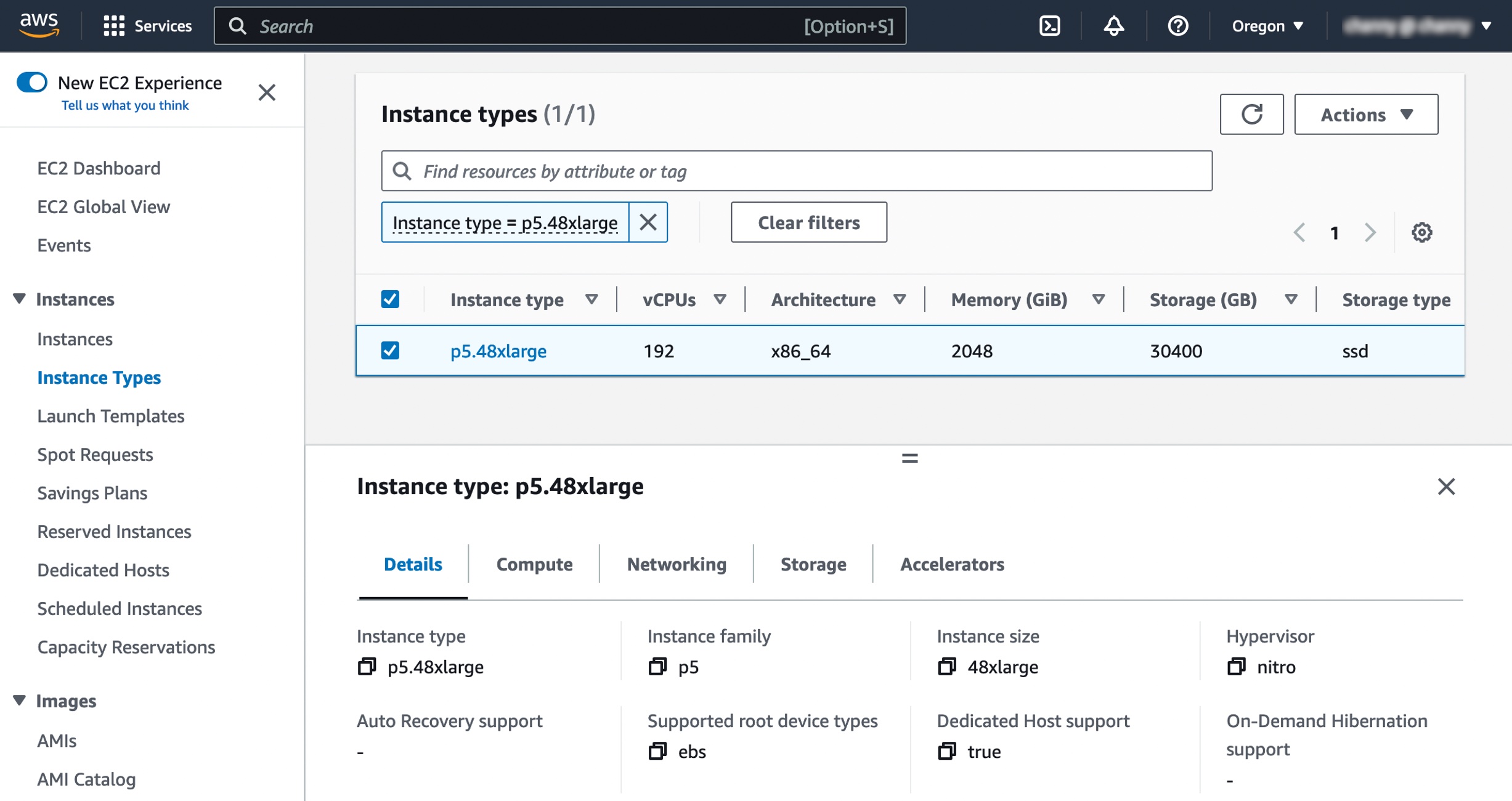
Here is the specs for this instance:
| Instance Size | vCPUs | Memory (GiB) | GPUs (H100) | Network Bandwidth (Gbps) | EBS Bandwidth (Gbps) | Local Storage (TB) |
| p5.48xlarge | 192 | 2048 | 8 | 3200 | 80 | 8 x 3.84 |
Here’s a quick infographic that shows you how the P5 instances and NVIDIA H100 Tensor Core GPUs compare to previous instances and processors:
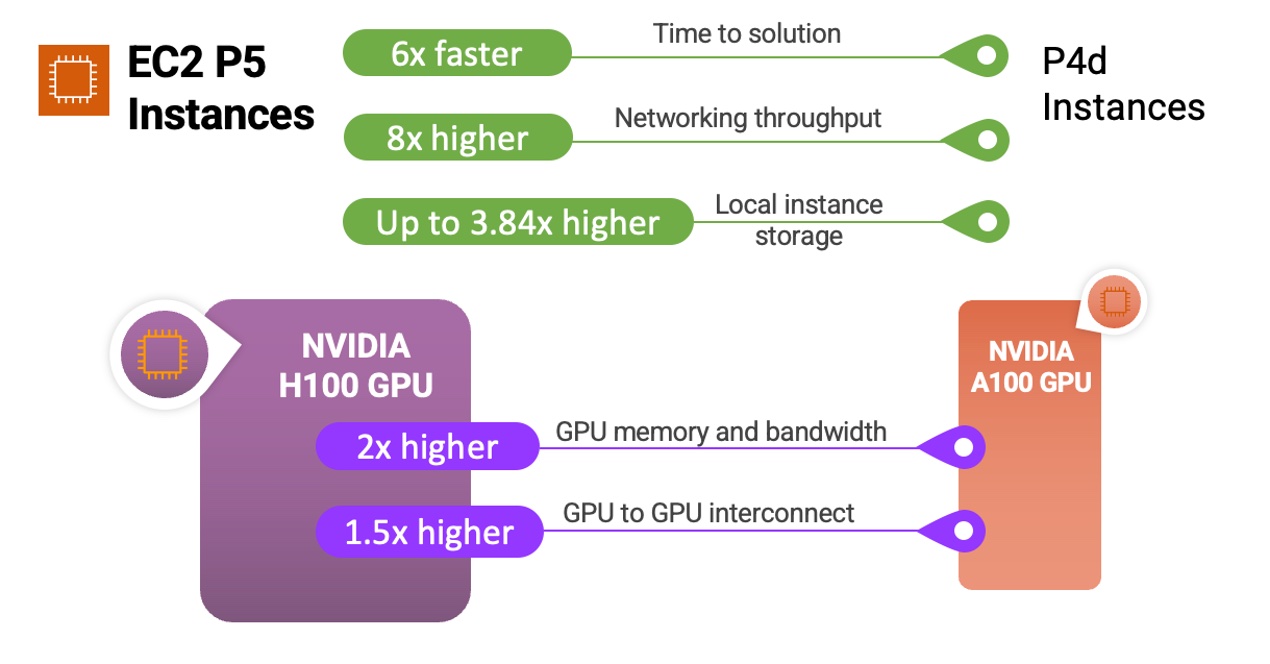
P5 instances are ideal for training and running inference for increasingly complex LLMs and computer vision models behind the most demanding and compute-intensive generative AI applications, including question answering, code generation, video and image generation, speech recognition, and more. P5 will provide up to 6 times lower time to train compared with previous generation GPU-based instances across those applications. Customers who can use lower precision FP8 data types in their workloads, common in many language models that use a transformer model backbone, will see further benefit at up to 6 times performance increase through support for the NVIDIA transformer engine.
HPC customers using P5 instances can deploy demanding applications at greater scale in pharmaceutical discovery, seismic analysis, weather forecasting, and financial modeling. Customers using dynamic programming (DP) algorithms for applications like genome sequencing or accelerated data analytics will also see further benefit from P5 through support for a new DPX instruction set.
This enables customers to explore problem spaces that previously seemed unreachable, iterate on their solutions at a faster clip, and get to market more quickly.
You can see the detail of instance specifications along with comparisons of instance types between p4d.24xlarge and new p5.48xlarge below:
| Feature | p4d.24xlarge | p5.48xlarge | Comparison |
| Number & Type of Accelerators | 8 x NVIDIA A100 | 8 x NVIDIA H100 | – |
| FP8 TFLOPS per Server | – | 16,000 | 6.4x vs.A100 FP16 |
| FP16 TFLOPS per Server | 2,496 | 8,000 | |
| GPU Memory | 40 GB | 80 GB | 2x |
| GPU Memory Bandwidth | 12.8 TB/s | 26.8 TB/s | 2x |
| CPU Family | Intel Cascade Lake | AMD Milan | – |
| vCPUs | 96 | 192 | 2x |
| Total System Memory | 1152 GB | 2048 GB | 2x |
| Networking Throughput | 400 Gbps | 3200 Gbps | 8x |
| EBS Throughput | 19 Gbps | 80 Gbps | 4x |
| Local Instance Storage | 8 TBs NVMe | 30 TBs NVMe | 3.75x |
| GPU to GPU Interconnect | 600 GB/s | 900 GB/s | 1.5x |
Second-generation Amazon EC2 UltraClusters and Elastic Fabric Adaptor
P5 instances provide market-leading scale-out capability for multi-node distributed training and tightly coupled HPC workloads. They offer up to 3,200 Gbps of networking using the second-generation Elastic Fabric Adaptor (EFA) technology, 8 times compared with P4d instances.
To address customer needs for large-scale and low latency, P5 instances are deployed in the second-generation EC2 UltraClusters, which now provide customers with lower latency across up to 20,000+ NVIDIA H100 Tensor Core GPUs. Providing the largest scale of ML infrastructure in the cloud, P5 instances in EC2 UltraClusters deliver up to 20 exaflops of aggregate compute capability.

EC2 UltraClusters use Amazon FSx for Lustre, fully managed shared storage built on the most popular high-performance parallel file system. With FSx for Lustre, you can quickly process massive datasets on demand and at scale and deliver sub-millisecond latencies. The low-latency and high-throughput characteristics of FSx for Lustre are optimized for deep learning, generative AI, and HPC workloads on EC2 UltraClusters.
FSx for Lustre keeps the GPUs and ML accelerators in EC2 UltraClusters fed with data, accelerating the most demanding workloads. These workloads include LLM training, generative AI inferencing, and HPC workloads, such as genomics and financial risk modeling.
Getting Started with EC2 P5 Instances
To get started, you can use P5 instances in the US East (N. Virginia) and US West (Oregon) Region.
When launching P5 instances, you will choose AWS Deep Learning AMIs (DLAMIs) to support P5 instances. DLAMI provides ML practitioners and researchers with the infrastructure and tools to quickly build scalable, secure distributed ML applications in preconfigured environments.
You will be able to run containerized applications on P5 instances with AWS Deep Learning Containers using libraries for Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS). For a more managed experience, you can also use P5 instances via Amazon SageMaker, which helps developers and data scientists easily scale to tens, hundreds, or thousands of GPUs to train a model quickly at any scale without worrying about setting up clusters and data pipelines. HPC customers can leverage AWS Batch and ParallelCluster with P5 to help orchestrate jobs and clusters efficiently.
Existing P4 customers will need to update their AMIs to use P5 instances. Specifically, you will need to update your AMIs to include the latest NVIDIA driver with support for NVIDIA H100 Tensor Core GPUs. They will also need to install the latest CUDA version (CUDA 12), CuDNN version, framework versions (e.g., PyTorch, Tensorflow), and EFA driver with updated topology files. To make this process easy for you, we will provide new DLAMIs and Deep Learning Containers that come prepackaged with all the needed software and frameworks to use P5 instances out of the box.
Now Available
Amazon EC2 P5 instances are available today in AWS Regions: US East (N. Virginia) and US West (Oregon). For more information, see the Amazon EC2 pricing page. To learn more, visit our P5 instance page and explore AWS re:Post for EC2 or through your usual AWS Support contacts.
You can choose a broad range of AWS services that have generative AI built in, all running on the most cost-effective cloud infrastructure for generative AI. To learn more, visit Generative AI on AWS to innovate faster and reinvent your applications.
— Channy