 |
With the vast amount of data being created today, organizations are moving to the cloud to take advantage of the security, reliability, and performance of fully managed database services. To facilitate database and analytics migrations, you can use AWS Database Migration Service (AWS DMS). First launched in 2016, AWS DMS offers a simple migration process that automates database migration projects, saving time, resources, and money.
Although you can start AWS DMS migration with a few clicks through the console, you still need to do research and planning to determine the required capacity before migrating. It can be challenging to know how to properly scale capacity ahead of time, especially when simultaneously migrating many workloads or continuously replicating data. On top of that, you also need to continually monitor usage and manually scale capacity to ensure optimal performance.
Introducing AWS DMS Serverless
Today, I’m excited to tell you about AWS DMS Serverless, a new serverless option in AWS DMS that automatically sets up, scales, and manages migration resources to make your database migrations easier and more cost-effective.
Here’s a quick preview on how AWS DMS Serverless works:
AWS DMS Serverless removes the guesswork of figuring out required compute resources and handling the operational burden needed to ensure a high-performance, uninterrupted migration. It performs automatic capacity provisioning, scaling, and capacity optimization of migrations, allowing you to quickly begin migrations with minimal oversight.
At launch, AWS DMS Serverless supports Microsoft SQL Server, PostgreSQL, MySQL, and Oracle as data sources. As for data targets, AWS DMS Serverless supports a wide range of databases and analytics services, from Amazon Aurora, Amazon Relational Database Service (Amazon RDS), Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon DynamoDB, and more. AWS DMS Serverless continues to add support for new data sources and targets. Visit Supported Engine Versions to stay updated.
With a variety of sources and targets supported by AWS DMS Serverless, many scenarios become possible. You can use AWS DMS Serverless to migrate databases and help to build modern data strategies by synchronizing ongoing data replications into data lakes (e.g., Amazon S3) or data warehouses (e.g., Amazon Redshift) from multiple, perhaps disparate data sources.
How AWS DMS Serverless Works
Let me show you how you can get started with AWS DMS Serverless. In this post, I migrate my data from a source database running on PostgreSQL to a target MySQL database running on Amazon RDS. The following screenshot shows my source database with dummy data:

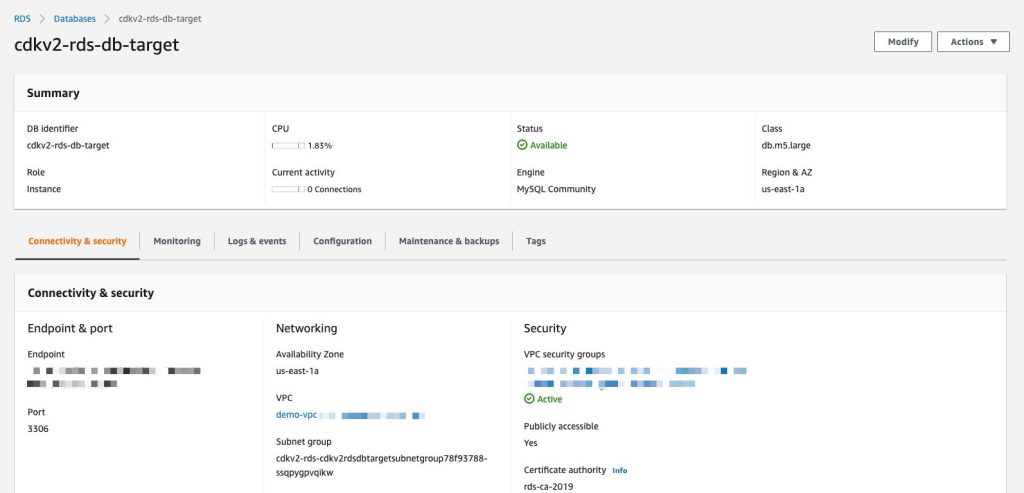
As for the target, I’ve set up a MySQL database running in Amazon RDS. The following screenshot shows my target database:
Getting starting with AWS DMS Serverless is similar to how AWS DMS works today. AWS DMS Serverless requires me to complete the setup tasks such as creating a virtual private cloud (VPC) to defining source and target endpoints. If this is your first time working with AWS DMS, you can learn more by visiting Prerequisites for AWS Database Migration Service.
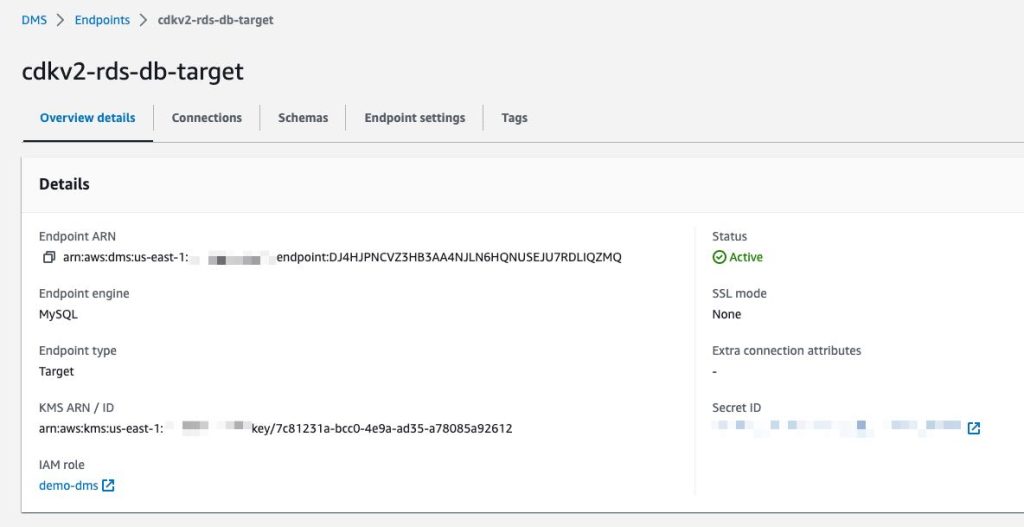
To connect to a data store, AWS DMS needs endpoints for both source and target data stores. An endpoint provides all necessary information including connection, data store type, and location to my data stores. The following image shows an endpoint I’ve created for my target database:
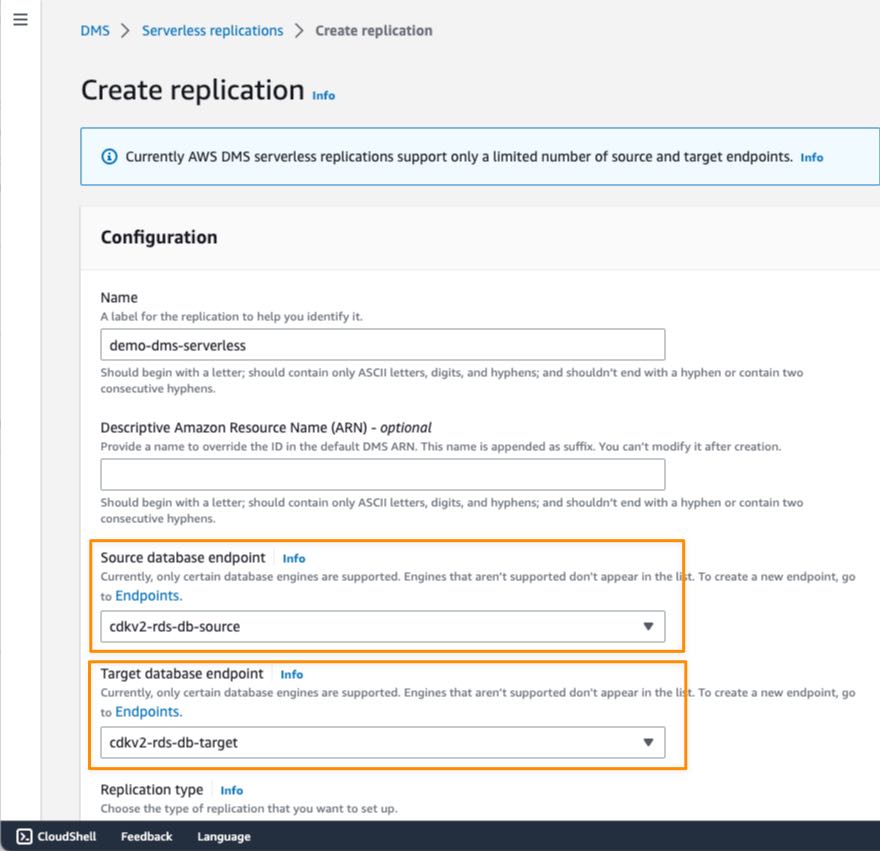
When I have finished setting up the endpoints, I can begin to create a replication by selecting the Create replication button on the Serverless replications page. Replication is a new concept introduced in AWS DMS Serverless to abstract instances and tasks that we normally have in standard AWS DMS. Additionally, the capacity resources are managed independently for each replication.

On the Create replication page, I need to define some configurations. This starts with defining Name, then specifying Source database endpoint and Target database endpoint. If you don’t find your endpoints, make sure you’re selecting database engines supported by AWS DMS Serverless.
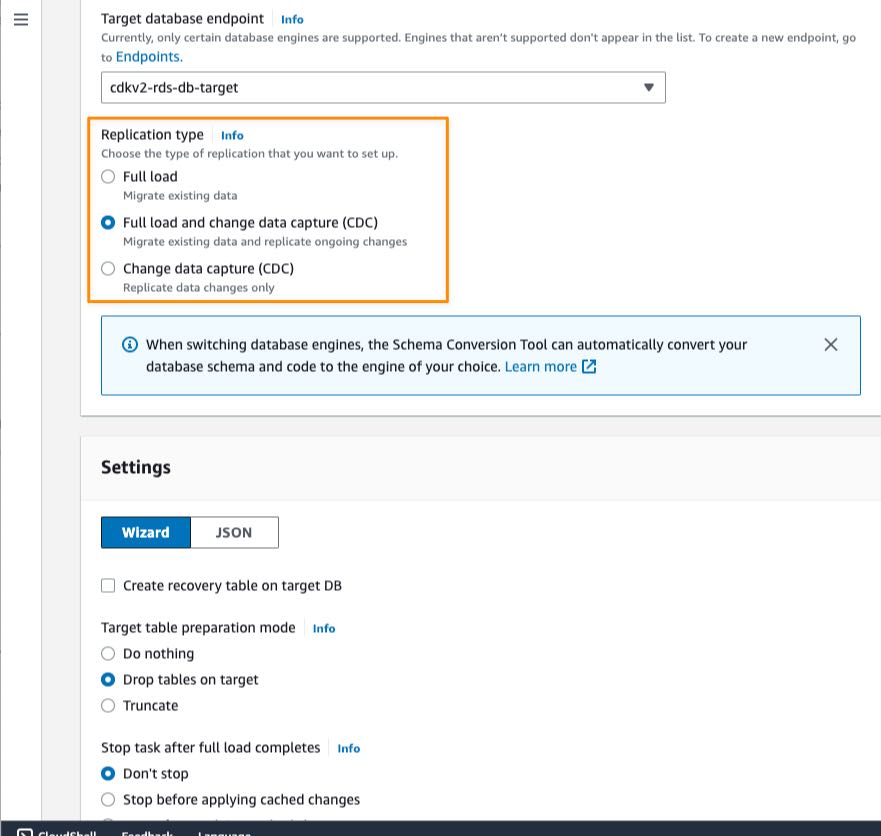
After that, I need to specify the Replication type. There are three types of replication available in AWS DMS Serverless:
- Full load — If I need to migrate all existing data in source database
- Change data capture (CDC) — If I have to replicate data changes from source to target database.
- Full load and change data capture (CDC) — If I need to migrate existing data and replicate data changes from source to target database.
In this example, I chose Full load and change data capture (CDC) because I need to migrate existing data and continuously update the target database for ongoing changes on the source database.
In the Settings section, I can also enable logging with Amazon CloudWatch, which makes it easier for me to monitor replication progress over time.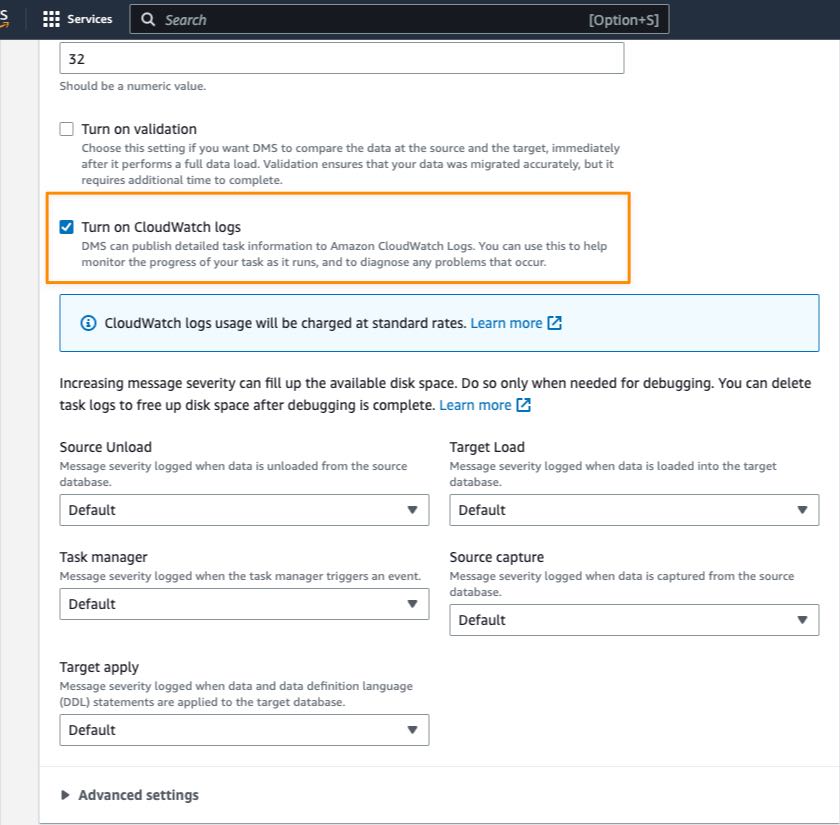
As with standard AWS DMS, in AWS DMS Serverless, I can also configure Selection rules in Table mappings to define filters that I need to replicate from table columns in the source data store.
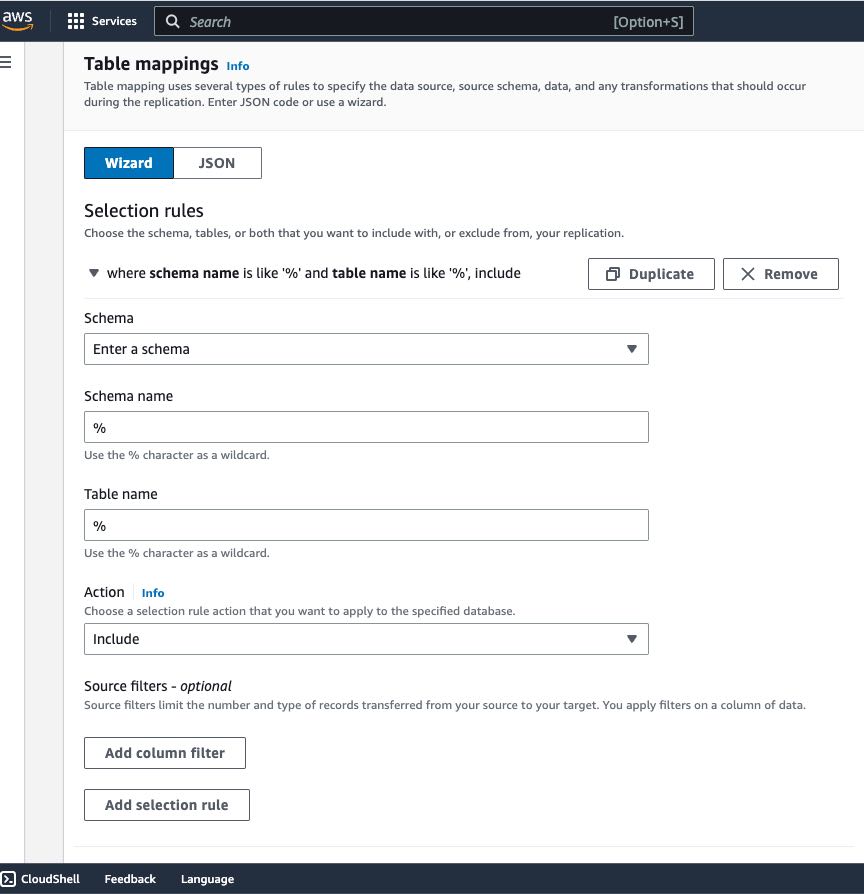
I can also use Transformation rules if I need to rename a schema or table or add a prefix or suffix to a schema or table.
![]()
In the Capacity section, I can set the range for required capacity to perform replication by defining the minimum and maximum DCU (DMS capacity units). The minimum DCU setting is optional because AWS DMS Serverless determines the minimum DCU based on an assessment of the replication workload. During replication process, AWS DMS uses this range to scale up and down based on CPU utilization, connections, and available memory.
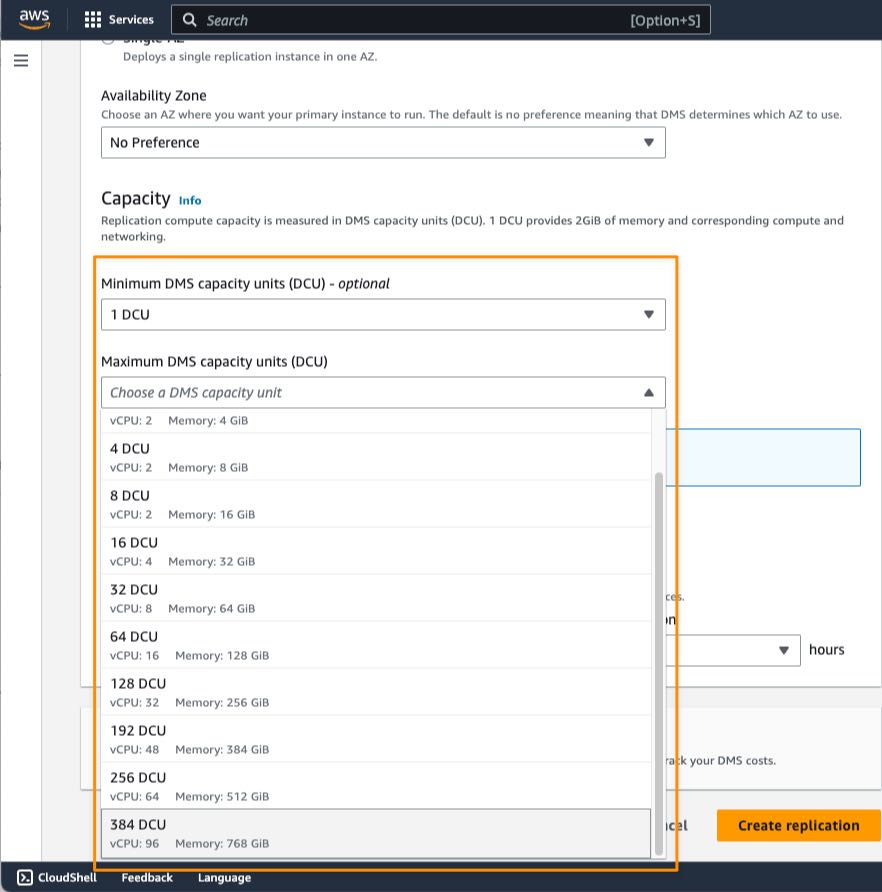
Setting the maximum capacity allows you to manage costs by making sure that AWS DMS Serverless never consumes more resources than you have budgeted for. When you define the maximum DCU, make sure that you choose a reasonable capacity so that AWS DMS Serverless can handle large bursts of data transaction volumes. If traffic volume decreases, AWS DMS Serverless scales capacity down again, and you only pay for what you need. For cases in which you want to change the minimum and maximum DCU settings, you have to stop the replication process first, make the changes, and run the replication again.
When I’m finished with configuring replication, I select Create replication.


When my replication is created, I can view more details of my replication and start the process by selecting Start.
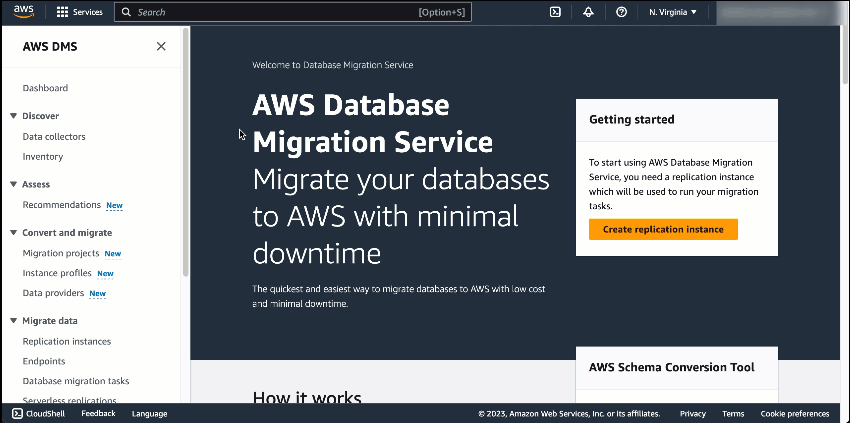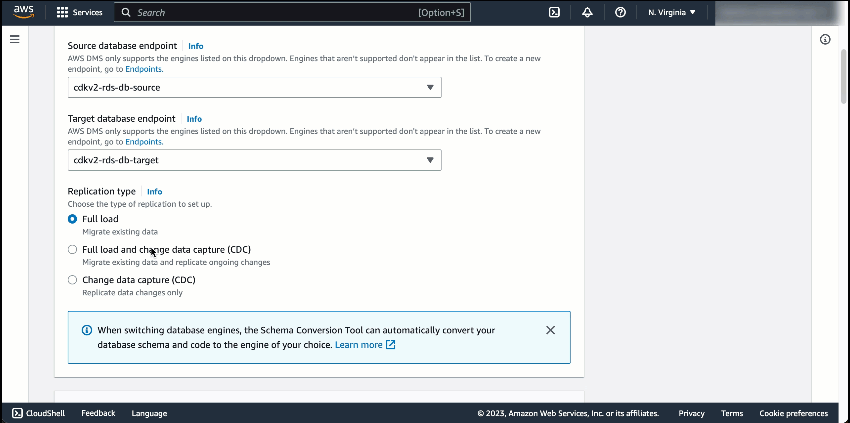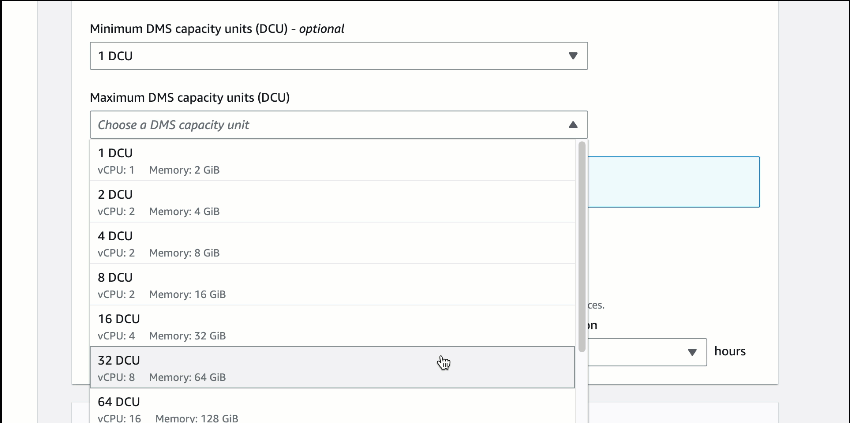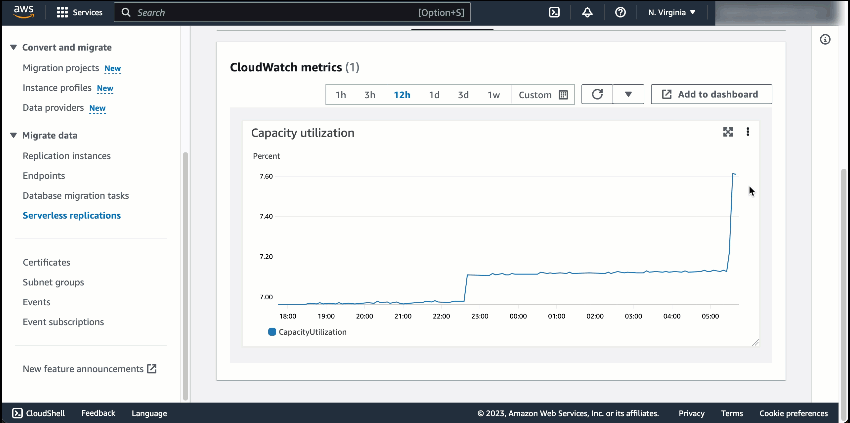
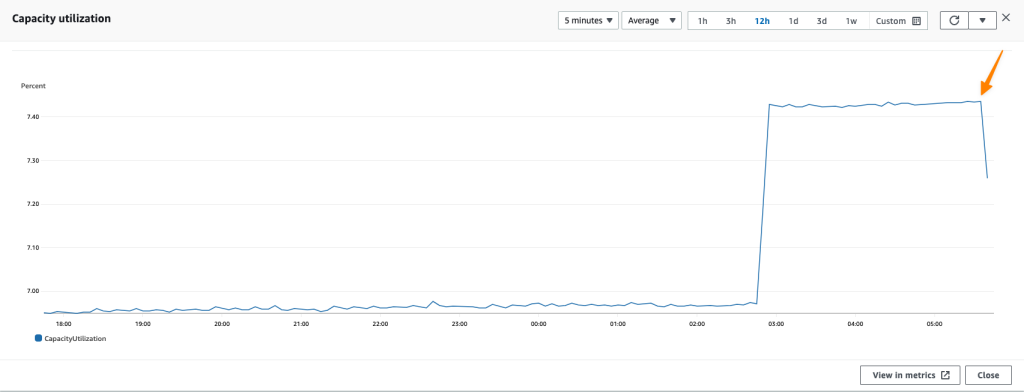
After my replication runs for around 40 minutes, I can monitor replication progress in the Monitoring tab. AWS DMS Serverless also has a CloudWatch metric called Capacity utilization, which indicates the use of capacity to run replication according to the range defined as minimum and maximum DCU. The following screenshot shows the capacity scales up in the CloudWatch metrics chart.
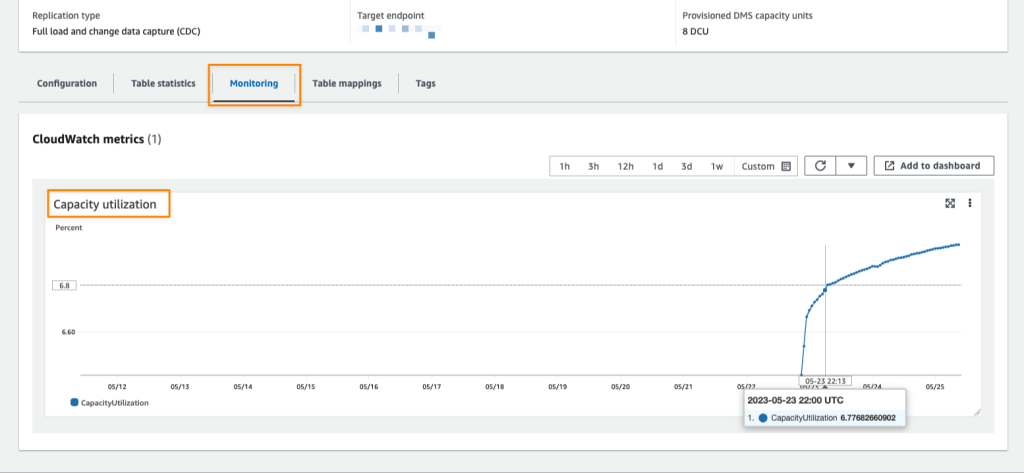
When the replication finishes its process, I see the capacity starting to decrease. This indicates that in addition to AWS DMS Serverless successfully scaling up to the required capacity, it can also scale down within the range I have defined.
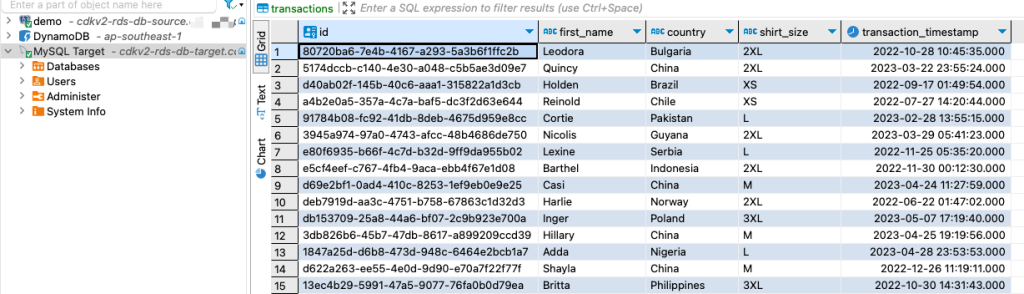
Finally, all I need to do is verify whether my data has been successfully replicated into the target data store. I need to connect to the target, run a select query, and check if all data has been successfully replicated from the source.
Now Available
AWS DMS Serverless is now available in all commercial regions where standard AWS DMS is available, and you can start using it today. For more information about benefits, use cases, how to get started, and pricing details, refer to AWS DMS Serverless.
Happy migrating!
—Donnie