 |
In 2019, we introduced Amazon SageMaker Studio, the first fully integrated development environment (IDE) for data science and machine learning (ML). SageMaker Studio gives you access to fully managed Jupyter Notebooks that integrate with purpose-built tools to perform all ML steps, from preparing data to training and debugging models, tracking experiments, deploying and monitoring models, and managing pipelines.
Today, I’m excited to announce the next generation of Amazon SageMaker Notebooks to increase efficiency across the ML development workflow. You can now improve data quality in minutes with the built-in data preparation capability, edit the same notebooks with your teams in real time, and automatically convert notebook code to production-ready jobs.
Let me show you what’s new!
New Notebook Capability for Simplified Data Preparation
The new built-in data preparation capability is powered by Amazon SageMaker Data Wrangler and is available in SageMaker Studio notebooks. SageMaker Studio notebooks automatically generate key visualizations on top of Pandas data frames to help you understand data distribution and identify data quality issues, like missing values, invalid data, and outliers. You can also select the target column for ML models and generate ML-specific insights such as imbalanced class or high correlation columns. You then receive recommendations for data transformations to resolve the issues. You can apply the data transformations right in the UI, and SageMaker Studio notebooks automatically generate the corresponding transformation code in the notebook cells that you can use to replay your data preparation pipeline.
Using the Built-in Data Preparation Capability
To get started, pip install and import sagemaker_datawrangler along with the pandas Python package. Then, download the dataset you want to analyze to the notebook working directory, and read the dataset with pandas.
import pandas as pd import sagemaker_datawrangler !aws s3 cp s3:///data.csv . df = pd.read_csv("data.csv")
Now, when you display the data frame, it automatically shows key data visualizations at the top of each column, surfaces data insights, detects data quality issues, and suggests solutions to improve data quality. When you select a column as the target column for ML predictions, you get target-specific insights and warnings, such as mixed data types in target (for regression use cases) or too few instances per class (for classification use cases).
In this example, I’m using the Women’s E-Commerce Clothing Reviews dataset that contains customer reviews and ratings for women’s clothing. This dataset was obtained from Kaggle and has been modified by Amazon to add synthetic data quality issues.

You can review the suggested data transformations to improve the data quality and apply them right in the UI. For a list of all supported data transformations, have a look at the documentation. Once you apply a data transformation, SageMaker Studio notebooks automatically generate the code to reproduce those data preparation steps in another notebook cell.
For my example, I select Rating as my target column. Target column insights tells me in a high-priority warning that this column has too few instances per class and with a medium-priority warning that classes are too imbalanced. Let’s follow the suggestions and drop rare target values and drop missing values. I will also follow the suggestions for some of the feature columns and drop missing values in the Review Text column and drop the Division Name column.
Once I apply the transformations, the notebook generates this code for me:
# Pandas code generated by sagemaker_datawrangler
output_df = df.copy(deep=True) # Code to Drop rare target values for column: Rating to resolve warning: Too few instances per class rare_target_labels_to_drop = ['-100', '100']
output_df = output_df[~output_df['Rating'].isin(rare_target_labels_to_drop)] # Code to Drop missing for column: Rating to resolve warning: Missing values output_df = output_df[output_df['Rating'].notnull()] # Code to Drop missing for column: Review Text to resolve warning: Missing values output_df = output_df[output_df['Review Text'].notnull()] # Code to Drop column for column: Division Name to resolve warning: Missing values output_df=output_df.drop(columns=['Division Name'])I can now review and modify the code if needed or start integrating the data transformations as part of my ML development workflow.
Introducing Shared Spaces for Team-Based Sharing and Real-Time Collaboration
SageMaker Studio now offers shared spaces that give data science and ML teams a workspace where they can read, edit, and run notebooks together in real time to streamline collaboration and communication during the development process. Shared spaces provide a shared Amazon EFS directory that you can utilize to share files within a shared space. All taggable SageMaker resources that you create in a shared space are automatically tagged to help you organize and have a filtered view of your ML resources, such as training jobs, experiments, and models, that are relevant to the business problem you work on in the space. This also helps you monitor costs and plan budgets using tools such as AWS Budgets and AWS Cost Explorer.
And that’s not all. You can now also create multiple SageMaker domains within the same AWS account to scope access and isolate resources to different teams or business units in your organization. Now, let me show you how to create a shared space for users within a SageMaker domain.
Using Shared Spaces
You can use the SageMaker console or the AWS CLI to create shared spaces for a SageMaker domain. To get started in the SageMaker console, go to Domains, select or create a new domain, and select Space management on the Domain details page. Then, select Create and give the shared space a name.
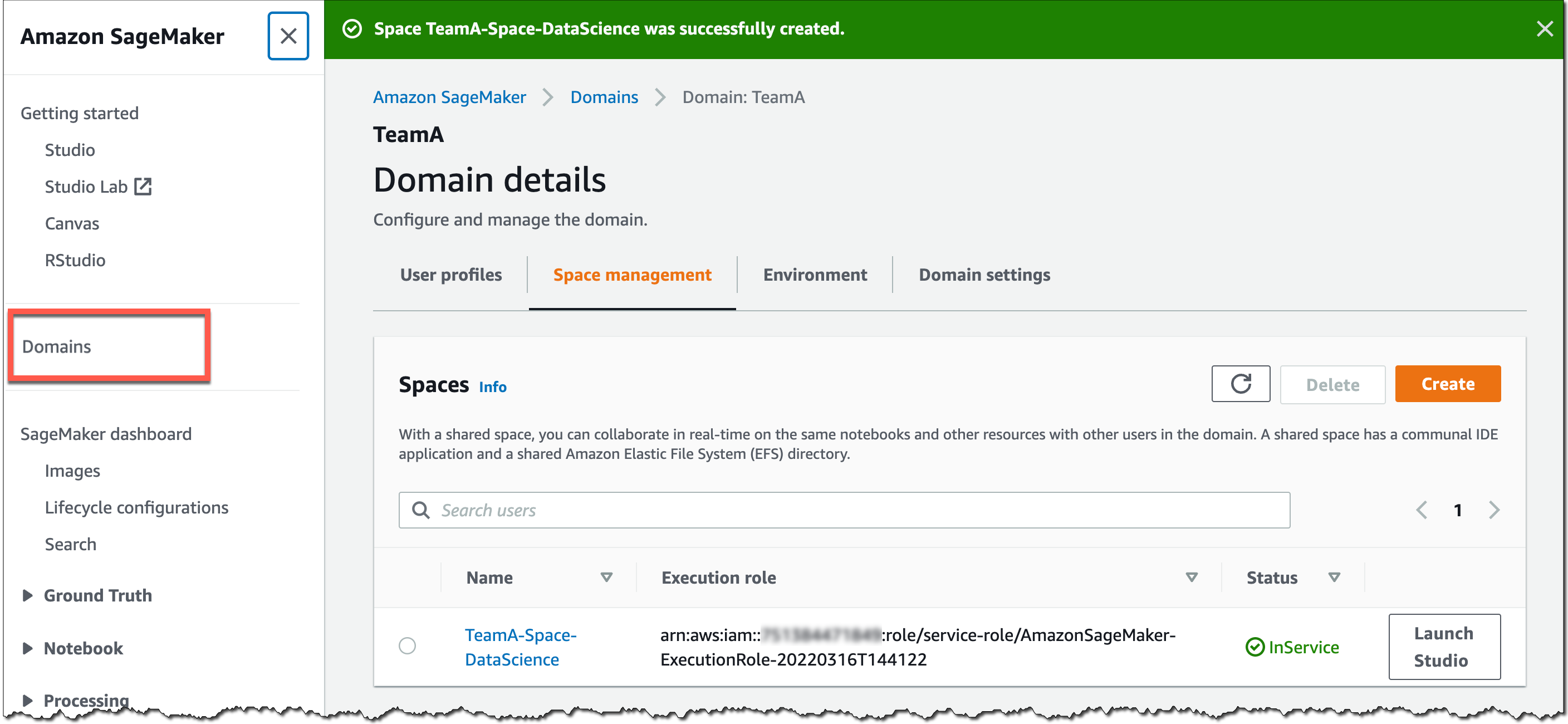
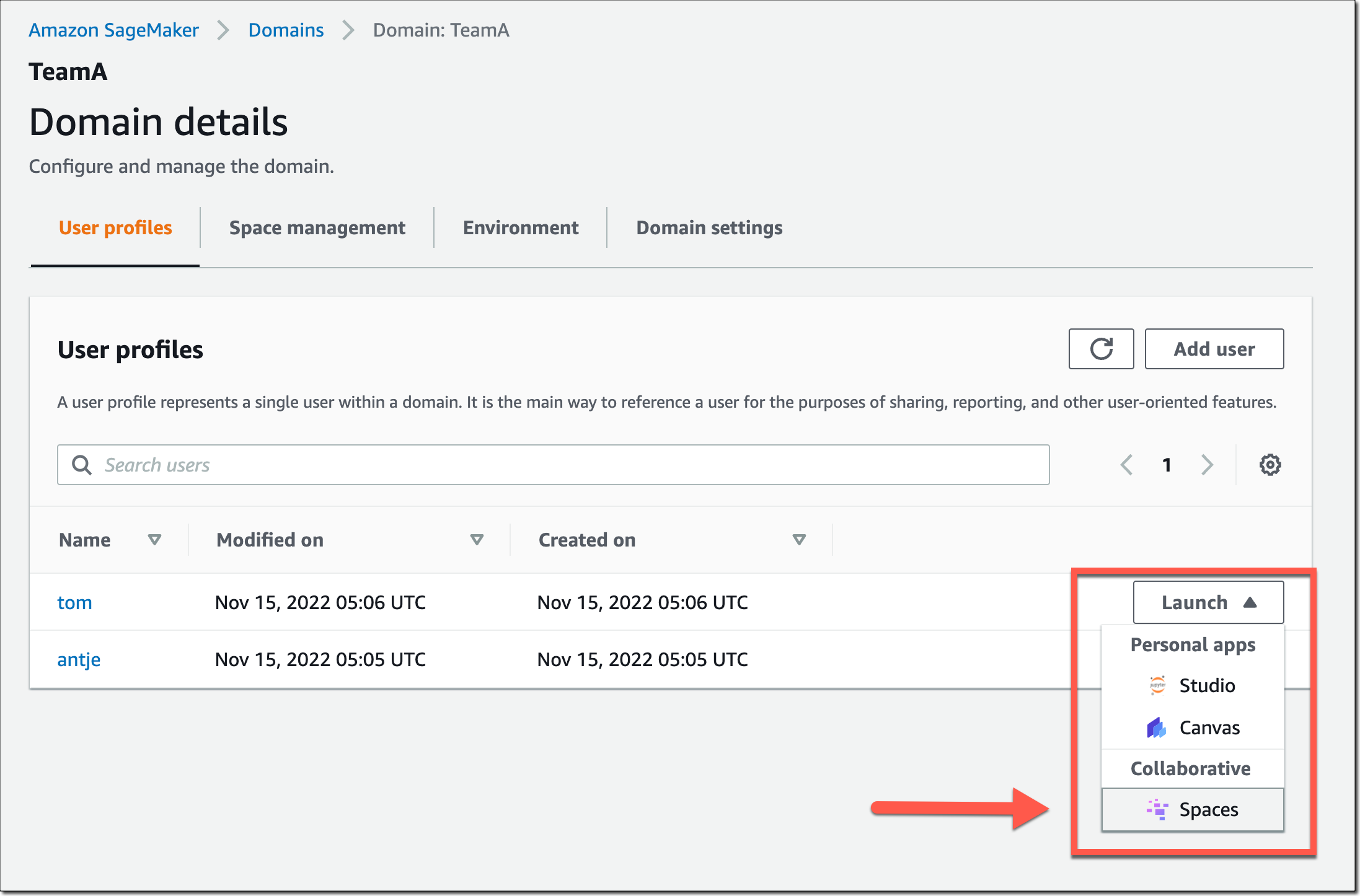
Users in this SageMaker domain can now launch and join the shared space through their SageMaker domain user profiles.
In a shared space, select the new Collaborators icon in the left navigation menu. You can now see who else is currently active in this space. The following screenshot shows user tom on the left, editing a notebook file. On the right, user antje sees the edits in real time, together with an annotation of the user name that currently edits that notebook cell.

New Notebook Capability to Automatically Convert Notebook Code to Production-Ready Jobs
You can now select a notebook and automate it as a job that can run in a production environment without the need to manage the underlying infrastructure. When you create a SageMaker Notebook Job, SageMaker Studio takes a snapshot of the entire notebook, packages its dependencies in a container, builds the infrastructure, runs the notebook as an automated job on a schedule you define, and deprovisions the infrastructure upon job completion. This notebook capability is now also available in SageMaker Studio Lab, our free ML development environment that provides the compute, storage, and security to learn and experiment with ML.
Using the Notebook Capability to Automate Notebooks
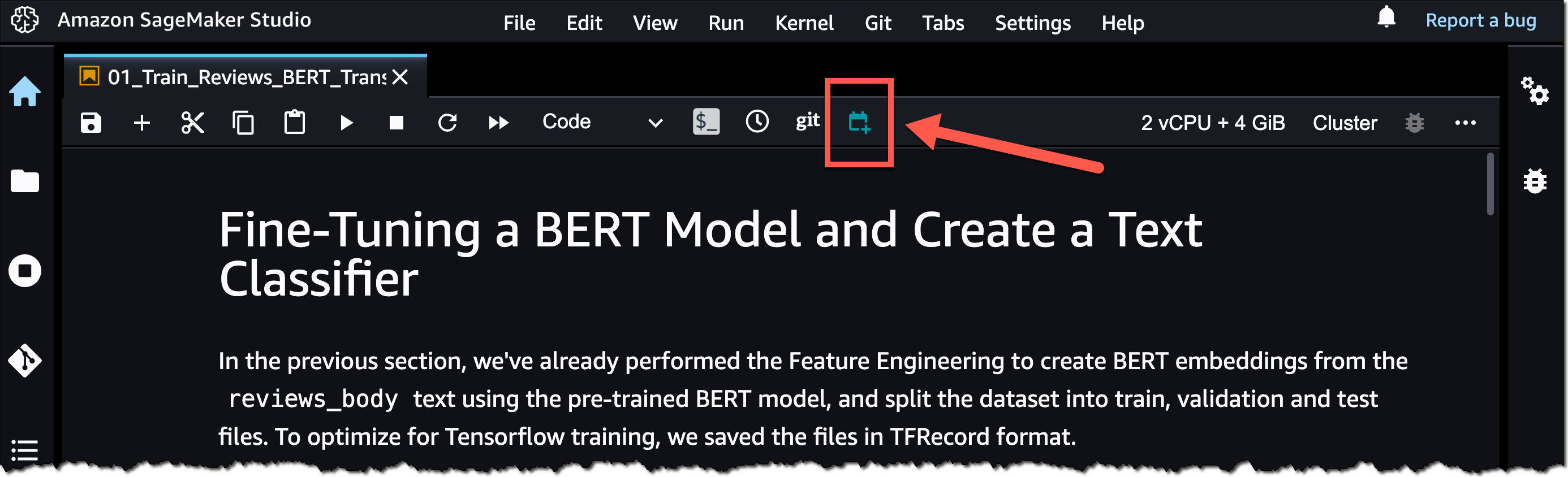
To get started, open a notebook file in SageMaker Studio. Then, right-click your notebook file and select Create Notebook Job or select the Create Notebook Job icon, as highlighted in the following screenshot.
Define a name for the Notebook Job, review the input file location, specify the compute type to use, and whether to run the job immediately or on a schedule. Then, select Create.
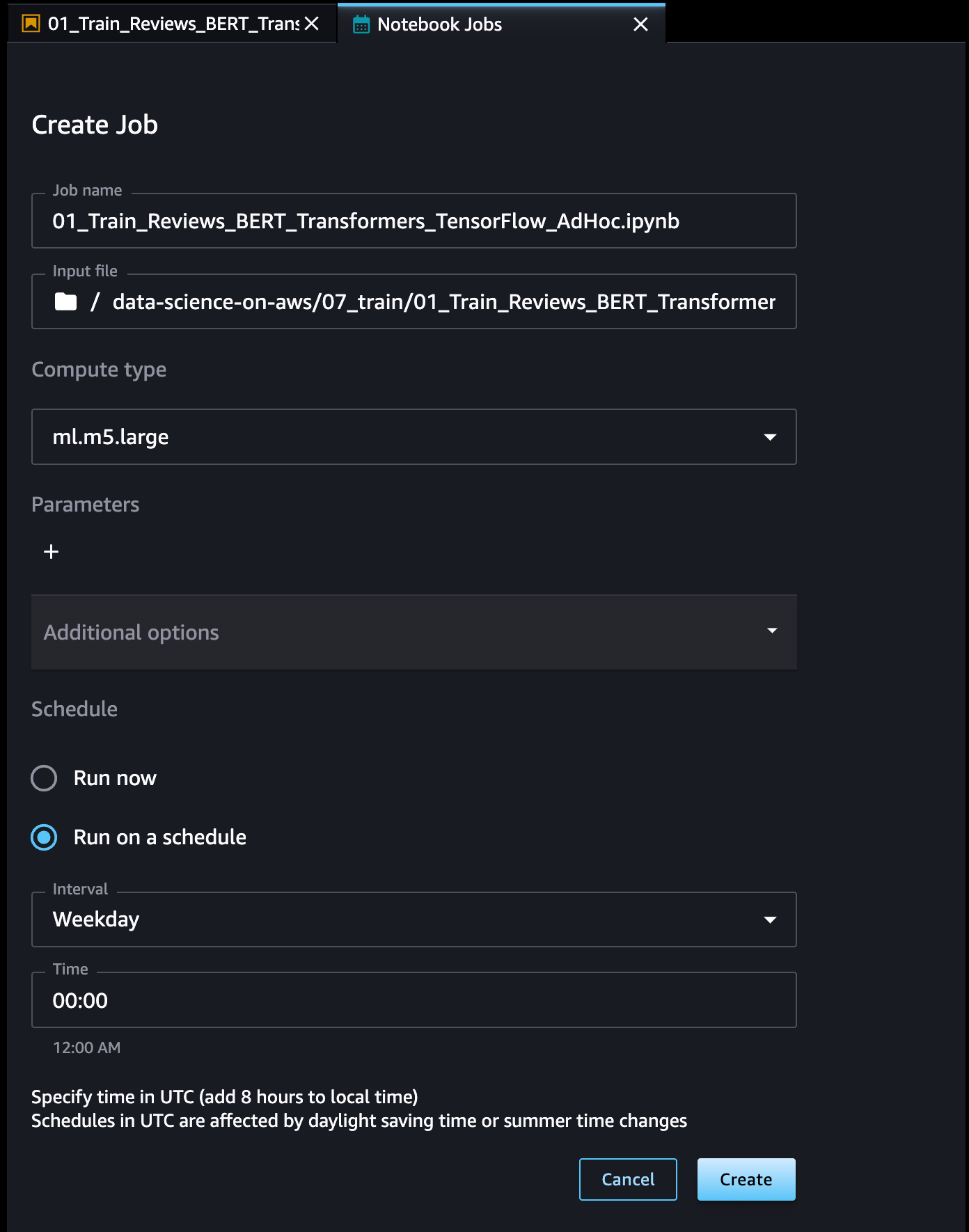
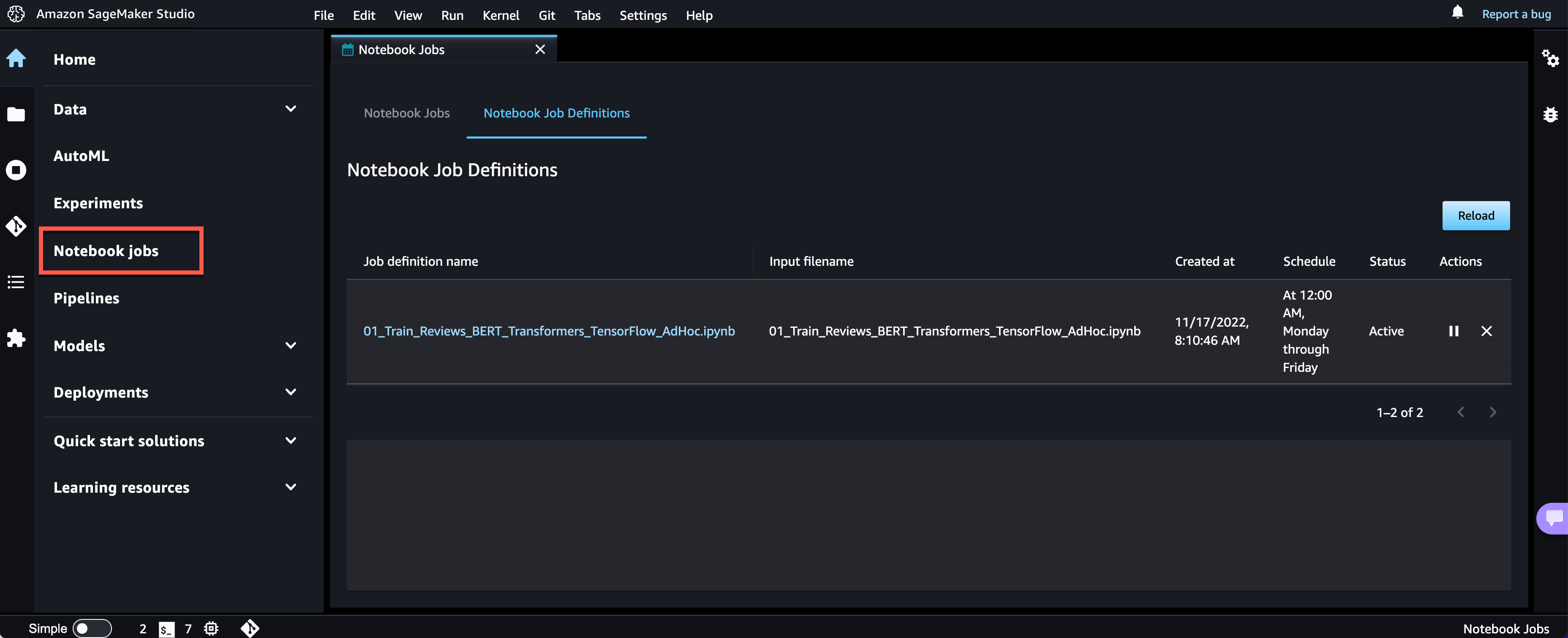
The Notebook Job has been created, and you can review all Notebook Job Definitions in the UI.
Now Available
The new Amazon SageMaker Studio notebook capabilities are now available in all AWS Regions where Amazon SageMaker Studio is available except for the AWS China Regions.
At launch, the built-in data preparation capability powered by SageMaker Data Wrangler is supported for SageMaker Studio notebooks and the following notebook kernel images:
- Python 3 (Data Science) with Python 3.7
- Python 3 (Data Science 2.0) with Python 3.8
- Python 3 (Data Science 3.0) with Python 3.10
- Spark Analytics 1.0 and 2.0
For more information, visit Amazon SageMaker Notebooks.
Start building your ML projects with the next generation of Amazon SageMaker Notebooks today!
— Antje